
This article is dedicated to a thorough analysis of aspects of testing big data applications, which is a little bit different from REST API testing in some specific technical methods.
The concept of Big Data
Every year, the term “big data” becomes more and more popular in the day-to-day activity of developers and testers.
According to Google Analytics, a high interest in big data appeared approximately at the beginning of 2012 and is constantly increasing from that time.
And Google also gives the following definitions:
- Big amount of system data;
- Big tables that can’t be analyzed with Excel;
- Such non-structured data from various sources that help to analyze customer behavior during their interaction with certain software.
We’d like to use the definition from Wikipedia (this will be the best variant). Big data is a field that treats ways to analyze, systematically extract information from, or otherwise, deal with data sets that are too large or complex to be dealt with by traditional data-processing application software.
Big Data in a cloud
Obviously, it’s not convenient and extremely expensive to store the data whose number is constantly growing on the local servers.
The field of big data has met global infrastructure perturbations since 2006 when the Internet community encountered Amazon Web Services.
It’s believed that from the middle of the current 2020, most servers will be stored in a cloud.
An example of Big Data in simple words
Big data is commonly displayed in the next way:
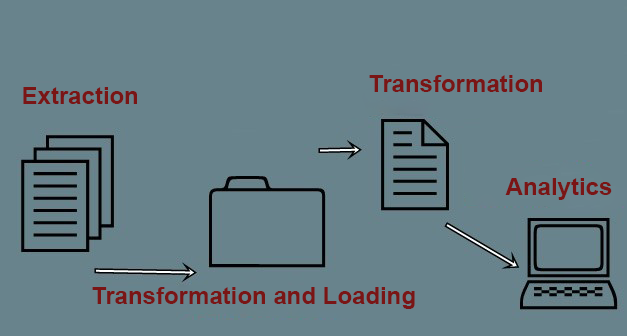
An Example of Big Data
- At the input, a web product comes from various sources. There are two examples of such inputs: flow data and package data;
- Information is extracted and structured in special staging tables. At this stage, the process of reduplication, separate editing of records that can’t be parsed before may be performed;
- After this, information from a staging table is structured and systematically transferred to a special store (data warehouse).
- Analytical reports can be created with the help of the information in such a store. As a result, a user receives data or system reports in a form of CSV files that can be uploaded to a server or a local store.
A visual example of big data
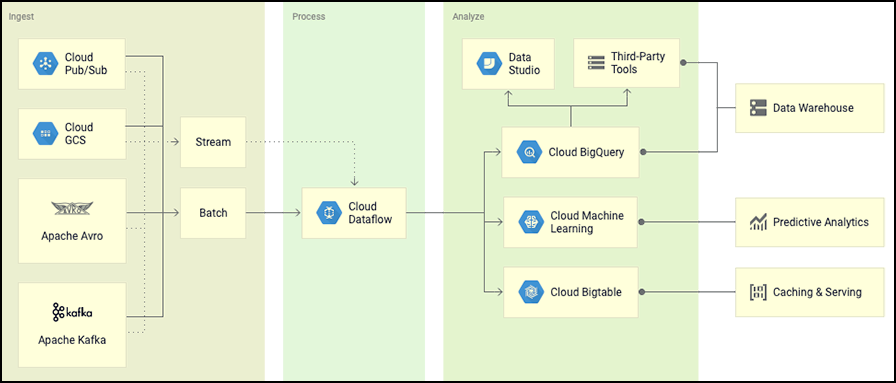
A Visual Example of Big Data on Google Cloud Platform
At the output, information is displayed in a form of batch files or certain flows.
With the help of a Cloud Dataflow framework, information is extracted, transformed, processed, and uploaded to DWH. This example shows using DWH together with BigQuery.
Special analytics and other computational processes are based on the received information.
How to test such processes?
According to the information we mentioned above, a tester has no access to front-end or API (back office) parts. He has only:
- Information that is almost completely uncontrolled;
- Data processing;
- Files, all possible tables, and some visualization at the output.
It’s logical that in this case, end-to-end testing provides the possibility to test, for example, that a line from the CSV file, at the input, went through all necessary alterations and is properly displayed in a final report.
It’s recommended to check if all data packages are correctly displayed in final reports or not.
Testing methods
Testing on stubs/mocks
Such tests help to test the correctness of transformation, proper downloading of information from the mocked data.
For example, we use CSV with some lines at the input. Negative tests should be executed separately.
Therefore, a tester can cover all data flow functions with tests in such a way but still, he/she can’t be absolutely sure that everything works properly in the online mode.
Testing with actual data
In this case, special tests for actual information are created but a tester doesn’t really understand how many of them will be in the future and how they will be displayed.
For example, a tester knows that all users from CSV users file should move from the USA to a staging table customers stage with USA national code and then – inside super_customers table.
This means that the tests that can be based on actual data are created (you can start from them, and not be afraid of a final result).
Combination of two approaches
You can create unit/integration tests on the basis of using mocked data.
Such an approach looks quite good since it gives the possibility to be absolutely sure that everything functions properly in the online mode.Also, when using both of them for testing big data, unit/integration tests give the possibility to perform tests for regression presence and test how proper and correct is the functioning of the overall established logic.
Also, a system of special monitoring with a constant list of various metrics and message sending should always function in the online mode. This should be also thoroughly tested.
Testing types
There are two types of tests: functional and non-functional tests. Non-functional tests include performance tests, system load tests, and system security tests.
Let’s analyze functional tests that are divided into 4 main subtypes more thoroughly:
- Metadata testing. Testing of data (view and length of a table), date of editing, a total number of lines and used indexes;
- Data validation testing. These tests help to check if all data have been properly transformed. For example, we can choose the process of transformation of Unix stamp according to a date;
- Completeness testing. Testing if all data sources function properly (information that has been successfully parsed, moved to a proper staging slot or has been simply recorded to logs);
- Accuracy testing. Testing current correctness of logic of data transformation from the staging level to the analytics level.
How can we automate such tests?
As for unit tests, you can easily use Junit/TestNG software.
For testing GCP, you can use a special Scio library by Spotify.
Functional tests for big data are really successful if you use the products together, for example, Cucumber BDD+Spring+Kotlin.
BDD can be used as a basis to describe all actions with information inside a test more efficiently. In this case, such test reports can be shown to a client who will see what and how has been tested.
To conclude, we’d like to say that big data is such a field that will be constantly developing, and specific technologies that impact its work will be improved.
Moreover, big companies are really interested in such a method of data storage, so product companies will have much work that should be properly tested (load testing services is an integral part of it).
Testing big data is still quite an unusual activity and the testing department has quite a complex task that if properly used, can be easily solved and help to find universal methodologies for frequent tests.








Leave A Comment