
Why Do We Need Logs? Information in HAR
In its technical structure, logs are of great help for programmers and sometimes testers to understand the nature of some error. The initial aim of logs is the protocoling of operations for further analysis by a system administrator, current diagnostic of an activity by a system, as well as statistics gathering.
Concept of HAR Files
HAR files are a special archive or log of multiple network requests, some kind of event log based on which specialists of technical support or programmers can check the browser network requests when it is some technical issue.
Also, this file can be used for gathering information to significantly improve performance and data security.
To understand better all the above, we have to look more closely into the structure of HAR file in a typical HTTP archive:
- log – a particular object that can present information on a structure of exported data;
- creator – information on a structure of developed browser objects;
- browser – name and the current version of a browser;
- pages – list of pages;
- page Timings – description of time needed to perform actions;
- entries – an object which is a particular amount of all the available HTTP requests ;
- request – information about executed queries;
- response – data about responses;
- cookies – list of all cookie files;
- headers – list of headers;
- queryString – names of all the parameters and values;
- postData – an object that describes posted information;
- params – list of data transferred into “postData”;
- a content – detailed description of objects in the “response” body;
- cache – data on the used cache;
- timings – detailed description of stages of request and received response.
Because of a huge amount of data (namely, more than 5000 lines in the .json format) based on the HAR file, developers can easily reproduce some actions on a web page and understand the reason for software malfunction.
One may wonder why it has to be json? Actually, it’s simple – most modern programming languages have a great library to change json testing information blocks.
In reality, there may be a defect in a test file (video) but on a programmer’s side, everything is fine. Hence, he/she cannot understand what the issue is. In such situations, the HTTP archive will be very useful.
The Process of Collecting Logs: An Illustrative Example
1. Creating HTTP Archive in Chrome
Go to the page with a problem. In the menu, find More tools > Developer tools > Network.
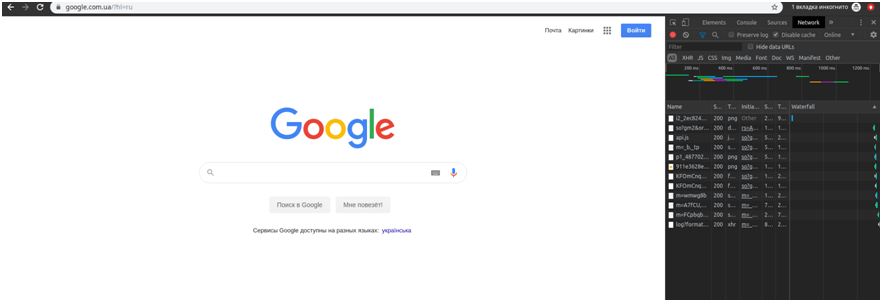
The Network tab in browser
As we see, request recording is inactive by default (you can tell by the gray color of the icon). Check the Preserve logs box.
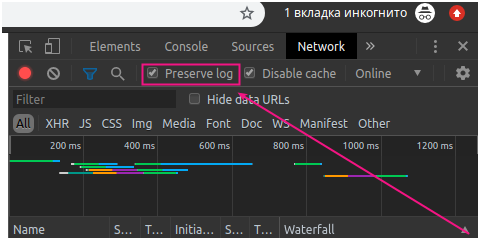
Check the Preserve logs box
Click on F5 or Ctrl+R to refresh the page.
Now, we can easily reproduce the process of receiving an error for its further debugging.
Then, you have to right-click on the request window and choose Save as HAR with Content.
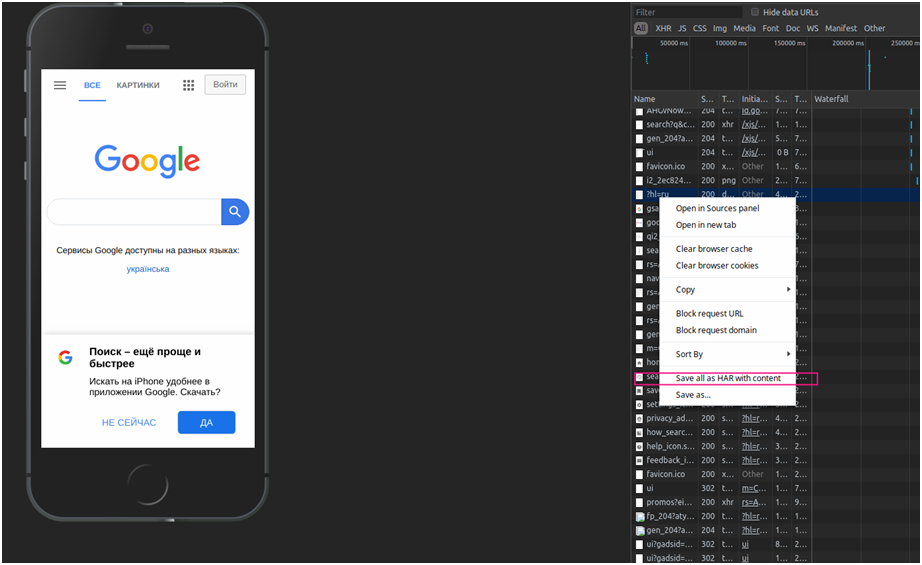
Choose Save as HAR with Content
Thus, you can easily add this file to the bug detected on the resource under test.
Besides, one can wonder how to view such a file? On the Internet, there are a lot of tools for such purposes. But, also, you can simply drop the file on the web browser window.
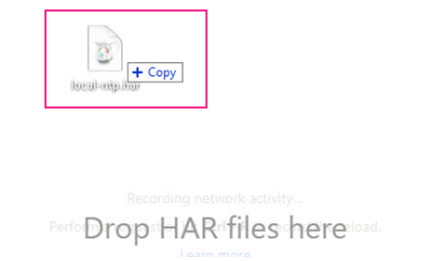
Drop the file in browser
2. Creating HTTP Archive in Mozilla Firefox
The first two steps are the same as users do in Google Chrome: go to Web Developer > Toggle Tools > Network. Or use a keyboard shortcut Ctrl+Shift+I.
Open the Network tab
Refresh the page.
Reproduce the current problem.
Click on Save All as HAR.
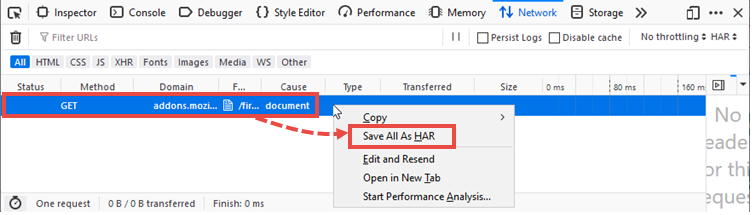
Click on Save All as HAR
That’s all. Now, users can view the content of a particular HAR file that potentially may have bugs and defects.
In fact, in Microsoft Edge, Safari, and Yandex Browser, such actions are taken in a similar way and order.
Short Conclusion
Skills to collect logs in different browsers allows programmer and sometimes QA engineer not only to gather much information about detected bugs but also to understand their technical nature that significantly accelerates the process of their fixation. These things, in turn, instantly improve the whole process of software development. This significantly affects the quality of web products.








Leave A Comment