






Зачем нужны логи? Информация в HAR
По своей технической структуре, логи очень сильно помогают программистам и порой тестировщикам понять, что конкретно означает та или иная ошибка, а также какова ее природа. Первоначальное предназначение логов – процесс протоколирования операций для последующего анализа системным администратором, текущее диагностирование системной активности, а также процедура сбора статистики.
Понятие HAR-файлов
HAR-файлы – это определенный архив или лог многочисленных сетевых запросов, своеобразный журнал событий, на основе которого специалисты технической поддержки или программисты могут проверить сетевые запросы веб-браузера в момент технической проблемы.
Также подобный файл может использоваться для сбора информации, чтобы максимально улучшить производительность и сохранность данных в нем.
Чтобы лучше понять все вышеизложенное, необходимо детально ознакомиться со структурой HAR-файлов в классическом HTTP архиве:
- log – определенный объект, который может предоставить данные касательно структуры экспортируемых данных;
- creator – данные о структуре разрабатываемых объектов браузера;
- browser – наименование и текущая версия браузера;
- pages – перечень страниц;
- page Timings – описание времени выполнения событий;
- entries – объект, который представляет собой определенный массив со всеми доступными HTTP-запросами;
- request – данные о выполненных запросах;
- response –данные об ответе;
- cookies – перечень всех файлов cookie;
- headers – перечень заголовков;
- queryString – наименование всех параметров и значений;
- postData – объект описывает опубликованную информацию;
- params – перечень переданных данных в «postData»;
- content – детальное описание объектов содержимого ответа в теле «response»;
- cache – данные об использованном кеше;
- timings – детальное описание стадий запроса и полученного ответа.
Из-за того, что всегда присутствует очень большой массив данных (а именно не менее 5000 строк в конкретном формате json), на основе HAR-файла разработчики могут запросто реконструировать определенные действия на веб-странице и понять причину неисправности ПО.
Можно задаться вопросом, почему именно json? На самом деле, все очень просто – больше половины современных языков программирования имеют отличную библиотеку обмена тестовыми информационными блоками json.
В реальности может возникнуть ситуация, когда в тестовом файле (видео) ошибка видна, но на стороне программиста все отлично. Следовательно, он не может конкретно понять, в чем именно баг. В подобных ситуациях, полезным как раз и будет HTTP-архив.
Процесс снятия логов: наглядный пример
1. Создание HTTP-архива в браузере Chrome
Переходим на страницу с проблемой. В меню находим вкладку Дополнительные инструменты > Инструменты разработчика > Сеть (network).

Вкладка Network в браузере
Как видно, запись запроса по умолчанию отключена (это можно определить по серому цвету иконки). Ставим галочку на поле Preserve log.
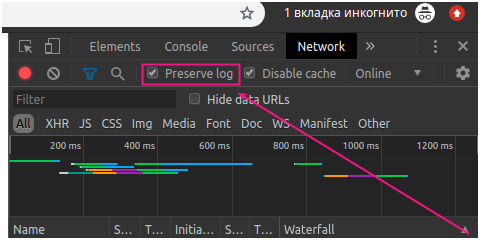
Ставим галочку на поле Preserve log
Нажимаем на кнопку F5 или Ctrl+R для выполнения перезагрузки страницы.
Теперь мы легко можем реконструировать процесс получения ошибки для последующего ее исправления.
Дальше необходимо нажать правой кнопкой мыши на окно запросов и выбрать соответствующий параметр Save as HAR with Content.
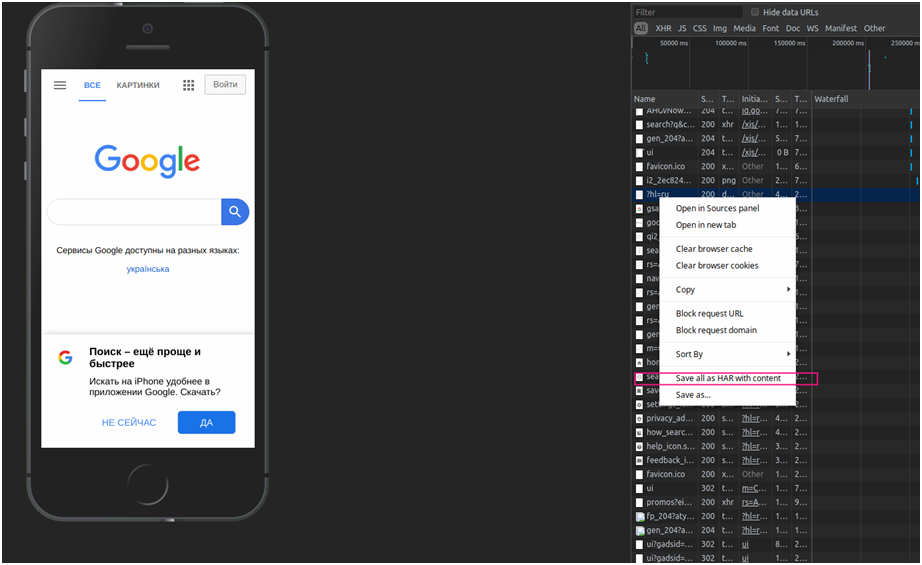
Выбираем параметр Save as HAR with Content
Подобный файл теперь можно просто добавить к найденному багу на просторах проверяемого ресурса.
Кроме того, может возникнуть вопрос, а как же просмотреть подобный файл? В сети есть масса инструментов для подобных целей, но также можно банально перетащить такой файл с места его хранения на «площадь» веб-браузера.
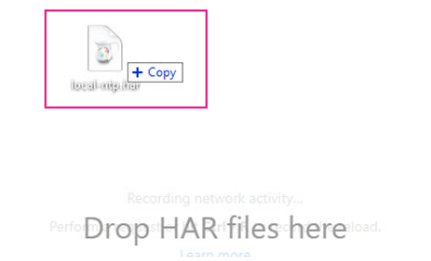
Перетаскиваем файл в браузер
2. Создание HTTP-архива в браузере Mozilla Firefox
Первые 2 шага аналогичны тем, что пользователи выполняют в браузере Google Chrome: открываем меню Веб-разработка > Инструменты разработчика > Сеть. Или одновременное нажатие на клавиши Ctrl+Shift+I.

Открываем вкладку Сеть в инструментах разработчика
Выполняем перезагрузку страницы.
Воспроизводим текущую проблему.
Выбираем опцию «Сохранить все как HAR».

Выбираем опцию «Сохранить все как HAR»
Все. Теперь пользователь может спокойно знакомиться с содержанием нужного HAR-файла, в котором потенциально могут храниться баги и дефекты.
По факту, для браузеров Microsoft Edge, Safari и Яндекс Браузер подобные операции выполняются по схожему сценарию и с той же последовательностью.
Краткие итоги
Владение определенными навыками снимать логи в различных веб-браузерах позволяет программисту и иногда QA-инженеру не только собирать много информации о найденных багах, но и разобрать их техническую природу, что естественным образом ускорит процесс исправления. Подобные вещи, в свою очередь, моментально улучшают общий процесс создания и построения программного обеспечения. От этого в большей степени и зависит качество веб-продуктов.



0 Comments