
В данном материале будут детально рассмотрены вопросы касательно особенностей процесса тестирования больших данных, которое отличается от процесса проверки REST API некоторыми характерными техническими методологиями.
Понятие больших данных
Итак, большие данные – это понятие, которое с каждым годом становится весьма популярным в повседневном обиходе разработчиков и тестировщиков.
Согласно аналитике Гугла, повышенный интерес к большим данным возник примерно в начале 2012 года и с тех пор только увеличивается.
Тот же Google дает такие определения:
- Большое системное скопление данных;
- Большие таблицы, которые невозможно просто проанализировать с помощью Excel;
- Своего рода неструктурированные данные из разнообразных источников, которые помогают проанализировать клиентское поведение при взаимодействии с определенным ПО.
Можно остановиться на понятии из Википедии (и это будет правильнее всего). Большие данные – сфера определения способа анализа и системного извлечения данных, которые очень сложны и их нельзя обработать классическими программами обработки.
Большие данные в облаке
Естественно, что при постоянном накоплении таких данных, хранить их на выделенных локальных серверах не очень практично и очень дорого.
С момента, как в 2006 году Интернет-сообщество познакомилось с Amazon Web Services, сфера больших данных претерпела глобальные инфраструктурные изменения.
Отмечается, что уже в середине текущего 2020 года, больше половины от всех серверов будут находиться в облаке.
Пример больших данных в упрощенной форме
Традиционно, большие данные можно графически отобразить таким способом:
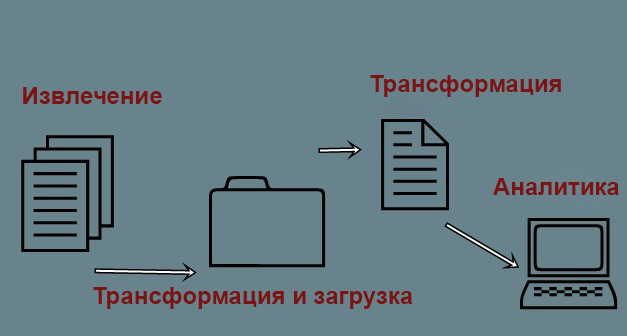
Пример больших данных
- На входе веб-продукт попадает из самых разнообразных источников. Таких «входа» два – потоковые данные и пакетные;
- Информация извлекается и комплектуется в специальные staging-таблицы. На данной стадии возможен процесс дедубликации, отдельное редактирование записей, которые ранее не получилось проанализировать;
- Затем информация из staging-таблицы группируется и системно передается в специализированное хранилище (data warehouse);
- На основании информации в таком хранилище создаются аналитические отчеты. И на выходе пользователь получает набор данных или системные отчеты в форме CSV-файлов, которые можно выгрузить на сервер или локальное хранилище.
Визуальный пример больших данных
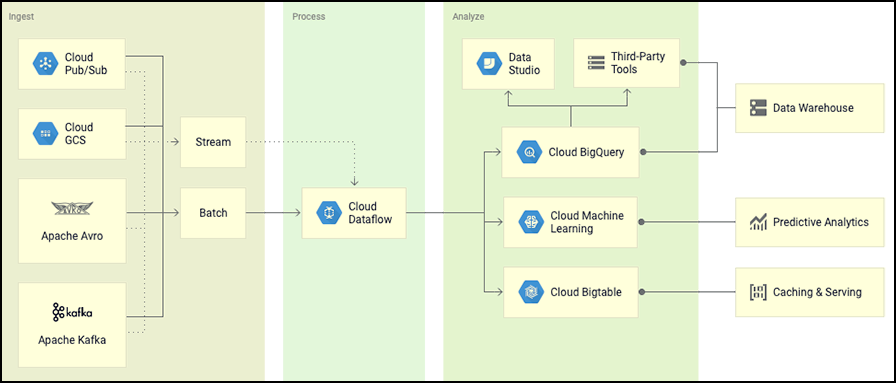
Визуальный пример больших данных на Google Cloud Platform
На выходе информация поступает в форме пакетных файлов или определенных потоков.
На основе фреймворка Cloud Dataflow информация извлекается, трансформируется, обрабатывается и выгружается в DWH (хранилище данных). На данном примере показано использование DWH в тандеме с BigQuery.
На базе поступившей информации строится специальная аналитика и прочие вычислительные процессы.
Как тестируются такие процессы?
Судя из всего вышеописанного, перед тестировщиком нет ни frond-end части, ни чистого API (back-office). Есть только:
- Входная информация, которой практически невозможно управлять;
- Обработка данных;
- Файлы, всевозможные таблицы и некая визуализация на выходе.
Логично, что в конкретной ситуации, сквозное тестирование – это возможность проверки, к примеру, что строка из CSV-файла, на входе, прошла все нужные трансформации и правильно продемонстрирована в финальном отчете.
В самом лучшем случае, стоит проверить, все ли пакеты данных правильно показаны в итоговых отчетах или нет.
Методология тестирования
Проверка на стабах/моках
Подобные проверки позволяют протестировать корректность трансформации, правильной выгрузки информации из mocked-данных.
К примеру, применяем CSV с несколькими строками на входе. Отдельно выполняются процедуры негативного тестирования.
То есть, подобным образом тестировщик может покрыть тестами все функции потока данных, но, при этом, он не сможет быть полностью уверенным в том, что все слаженно функционирует онлайн.
Проверка на реальных данных
В подобном случае создаются специальные тесты для реальной информации, но тестировщик до конца не понимает, сколько их будет в сумме и в каком виде они отобразятся.
К примеру, проверяющий знает, что все пользователи из файла CSV users должны на входе из страны США попасть в staging-таблицу customers_stage с национальным кодом страны USA, а уже оттуда – внутрь таблицы super_customers.
Это значит, что создаются такие тесты, которые могут базироваться на данных, существующих в реальном распоряжении (от них и можно отталкиваться без страха за конечный результат).
Комбинация двух подходов
При желании модульные/интеграционные тесты можно создать на основании использования подхода применения mocked-данных.
Такой подход видится весьма оптимальным, так как дает возможность полностью убедиться в том, что все правильно функционирует онлайн.И еще. При сдвоенном подходе в тестировании больших данных, модульные/интиеграционные тесты дают возможность проводить проверки на наличие регрессии и тестировать, насколько корректно и правильно функционирует вся заложенная логика.
Также, онлайн всегда должна функционировать система особого мониторинга с постоянным сбором различных метрик и отправка уведомлений. Это все тоже должно быть тщательно проверено.
Типы тестирования
Есть два вида проверок: функциональные тесты и нефункциональные. Нефункциональные включают в себя проверки на производительность, нагрузку системы и системную безопасность.
Более детально можно разобрать именно функциональные тесты, которые подразделяются на 4 базовых подвида:
- Тестирование метаданных. Выполняется тестирование данных (вид и длина таблицы), даты редактирования, суммы строк, используемых индексов;
- Тестирование валидации данных. С помощью эти тестов можно проверить, корректно ли все данные прошли процесс трансформации. Для примера, можно взять процесс преобразования Unix-timestamp (временной метки) к дате;
- Проверка согласованности. Тестируется, все ли источники данных корректно функционируют (информация, которая удачно проанализировалась, попала в нужный staging-слот или просто записалась в логи);
- Проверка точности. Проверка текущей корректности логики трансформации данных по пути от staging до analytics-слоя.
Как успешно автоматизировать такие проверки?
Если речь идет о модульных тестах, можно запросто применять программу Junit/TestNG.
Для GCP можно использовать специальную библиотеку Scio производства Spotify.
Практика показывает, что функциональные тесты для больших данных имеют успех, если использовать продукты в связке, например – Cucumber BDD+Spring+Kotlin.
На основе BDD можно наиболее продуктивно описывать все действия с информацией внутри теста. При этом, такие тесовые отчеты можно демонстрировать клиенту, который будет наглядно видеть что и как было протестировано.
И в завершении хотелось бы отметить, что большие данные – та сфера знаний, которая постоянно будет исключительно развиваться, а узкоспециализированные технологии, влияющие на ее работу, будут улучшаться.
Кроме того, уже виден особый интерес больших компаний к этому методу хранения данных, а значит у продуктовых компаний будет много работы, которую нужно будет хорошо тестировать (услуги по нагрузочному тестированию – как само собой разумеющееся).
Проверять большие данные пока еще немного необычно, поэтому, перед отделом тестирования стоит весьма непростая задача, которую, при должном подходе, можно уверенно решать и находить универсальные методологии для частых проверок.








Оставить комментарий