
В чем суть
Если взять любое программное обеспечение и сравнить его с живым организмом, то окажется, что баг (ошибка, дефект) – это болезнь, которая поражает организм и наносит определенный вред. Проявление такой болезни может быть спровоцировано целым рядом негативных факторов, особенно если рассматривать веб-продукт в качестве старта.
Иногда причинно-следственная закономерность очень запутанная и ошибка, которую нашел тестировщик во время поиска багов – итог целого комплекса выполненных действий.Как и во время борьбы с человеческими недугами, где кроме пациента никто не сможет лучше описать текущие симптомы болезни, так и ни один QA специалист не сможет поведать, что случилось на самом деле лучше, чем непосредственно программа (утилита, веб-продукт).

Логирование как составная часть сборки ПО
Что необходимо сделать
Итак, чтобы программа могла сама сообщить нам о том, что же именно ее беспокоит, необходимо заручится поддержкой нескольких проверенных и бесплатных решений – Kibana, ElasticSearch и LogStash – которые запросто можно соединить в единый компонент.

Ключевые продукты тестирования через логирование
Немного информации:
- ElasticSearch – автоматически настраивающаяся база данных с отменным поиском по текстовым блокам;
- LogStash – синхронизатор с ElasticSearch и сборщик логов из открытых источников;
- Kibana – интуитивно понятный веб-интерфейс с неограниченным количеством дополнений и расширений.
Как происходит работа связанных компонентов?
Допустим, у нас есть приложение, которое может сохранять логи на сервере. LogStash моментально в инкрементальной форме передает информацию на ElasticSearch, внутрь базы данных. Пользователь заходит в Kibana и видит список всех заранее сохраненных логов.
Хорошо продуманная работа утилиты Kibana позволит отображать данные в форме графиков, таблиц и интерактивных карт.
Пример №1 – тестирование через логирование на основе социальной сети
Теперь представьте, что в наших руках находится вполне сформированная социальная сеть закрытого доступа, которая была предварительно проверена на 100% работоспособность при любых обстоятельствах. Ее сущность – реальное время, она выстроена на сокетах, где очень много сторонних сервисов и информации.
За основу были взяты React+Redux. Оговоримся сразу, подход логирования никак не привязан к процессу логирования.
Попробуем провести логирование продукта, чтобы ответить на вопрос: возможно ли подобным образом сократить время на проверку ПО.
Для этого:
- Подбираем оптимальный логгер;
- Создаем класс для надежного хранения всех зафиксированных манипуляций клиента, которые проходят ДО наступления ошибок;
- Проводим логирование для взаимодействия с сервером;
- Проводим логирование сокета соединения;
- Отправляем данные на ElasticSearch.
Итак, начнем!
Выбираем логгер для нашего продукта. Если это часть back-end, можно воспользоваться программой Winston. Для front-end можно применить js-logger, так как его параметры поддерживают все базовые методы логирования – error, debug, log, info, warn.
Логгер обязательно должен передавать информацию в коллекцию с определенным лимитом. Если вы превысите лимит, то первый элемент будет удален. Подобная закономерность внедрена для того, чтобы не пересылать достаточно громоздкие и тяжелые данные.

Пример логгера
Внутрь стека мы запросто можем внести метаданные: актуальный язык, определенную системой локализацию, актуальную теку, данные о браузере и системе, список последних действий и userID.
К слову, userID очень важен, ведь именно благодаря его наличию у проектной команды есть возможность понимать, у какого именно тестировщика на проекте произошла ошибка.
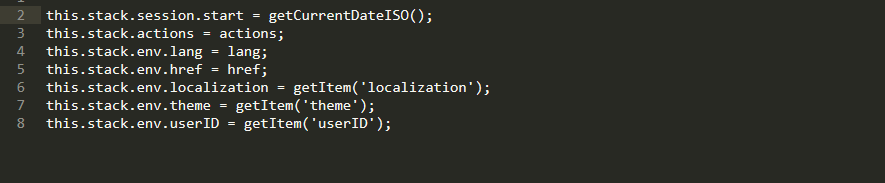
Данные стека
Для социальной сети мы применили Redux. Его функционал позволяет импортировать внутрь программного кода логгер через middleware, что существенным образом упрощает процесс сбора данных.
Наличие префикса redux позволяет понять, на каком именно слое утилиты случилась зафиксированная ошибка.
Фиксируем все выполненные действия с пометкой redux и добавляем в список те, которые уже пришли с определенным действием:
const logActionsMiddleware = store => next => action => {
let payload = Object.keys(action)
.filter(key => key !== ‘type’)
.reduce((payload, key) => {
payload[key] = action[key];
return payload;
}, {});
logger.log(`redux|${action.type}|${JSON.stringify(payload)}`);
return next(action);
};
Чтобы выполнить всю работу по покрытию сервера логами можно использовать axinos. С его помощью можно вставить middleware внутрь обработки всех существующих запросов. Подкрепим наш логгер на все ошибки от сервера. Теперь каждый запрос будет обрабатываться, и если сервер не работает или не прислал что-то в ответ, мы точно об этом узнаем:
rest.interceptors.request.use(
config => config,
error => {
if (error.message) {
logger.error(error.message);
}
return Promise.reject(error);
}
);
rest.interceptors.response.use(
response => response.data,
error => {
if (error.message) {
logger.error(error.message);
}
return Promise.reject(error);
}
);
С сокетами все гораздо проще и понятнее. С помощью контракта мы решаем, что каждое сообщение будет иметь свой персонализированный статус. Если какой-то статус прибыл с ошибкой, мы его начинаем обрабатывать.
this.socketManager.io.on(SOCKET_EVENTS.NOTIFICATION, notification => {
if (notification.status === ‘error’) {
logger.info(`socket|Error ${notification.message}`);
this.props.onAuthUpdate();
}
else {
this.props.onAddNotification(data);
}
});
Также помним о:
- Применении понятных сообщений;
- Дроблении сложных алгоритмов и разбавлении их логами;
- Избежании ситуации с избыточными логами;
- Логировании участков, структур, особенно ошибок.
При необходимости мы можем расставлять логи внутри компонентов, в catch методах React.
Настоятельно рекомендуется ставить название компонента, чтобы во время минифицированной версии прекрасно понимать, в каком именно компоненте у нас произошла ошибка.
static displayName = ‘MyComponent’;
…
componentDidCatch(err) {
logger.error(`react.${this.displayName}|${err.toString()}`)
}
Во все сложные алгоритмы необходимо добавлять логи, покрывая при этом наиболее узкие места продукта.
После этого мы подписываемся на onerror и при возникновении ошибки посылаем в Elastic сведения со всеми данными из стека:
window.onerror = (errorMsg, url, lineNumber, lineCount, trace) => {
// create critical error
let critical = {};
critical[CRITICAL] = serializeError(trace, lineNumber);
let criticalData = mixParams.call(this, critical, true);
this.stackCollection.add(criticalData);
// get stack data
let stackData = this.getStackData();
// send log to server
this.sendLogToServer(stackData);
};
Что имеем в итоге:
- Мы создали все необходимые условия, чтобы сохранять действия, которые предшествуют моменту наступления ошибки, а также прикрепили набор метаданных;
- Если случается ошибка, то информация отправляется на ElasticSearch;
- QA специалист, который находит дефект, может прикрепить его в запрос с оригинальным ID номером;
- При переходе в Kibana можно фильтровать данные по ID, прекрасно понимая, когда произошла ошибка, с последующей фиксацией бага.
Это все хорошее, но не идеальное решение. Нет информации с back-end, данные представлены не в слишком развернутой форме. Но если постараться, можно сделать так, чтобы было все намного лучше!
Пример №2 – тестирование на базе готового программного продукта (CleverBush)
Представим, что у нас есть готовый продукт, который прошел все стадии разработки – от создания ПО, до разработки графики (коллажей и редакторов).
Теперь на основании возможностей первого примера мы постараемся улучшить свои умения тестировать через логирование.
Допустим, на этом проекте нет никакого Redux. Что теперь делать? Существует сразу 3 подхода, как можно организовать быстрое логирование продукта:
- @ — декораторы – особый способ для обвертки метода в функцию, внутри которой можно выполнять логирование как до выполнения метода, так и после. С таким подходом можно справиться, если у вас, к примеру, исходный программный код;
- Proxy – хороший способ для интеграции кода в методы при взаимодействии с объектом. Жаль, что он поддерживается не всеми современными браузерами;
- Создавать программный код сразу же с логами – отличный вариант при разработке с самого начала. В таком случае от вас ничего не скроется и программный код будет максимально покрыт логированием.
А если у нас традиционный стартап, то требований особых нет, и не всегда все действия выглядят логичными.
Если QA специалист не понимает суть поведения – это ошибка, с которой нужно что-то делать. К тому же, не все баги могут привести к критическому состоянию. Под эти цели на стейджинге можно создать кнопку в шапке сайта для принудительной процедуры отправки логов на сервер. QA видит, что система функционирует не так как нужно, жмет на кнопку и повторяет аналогичное действие, что и на onerror.
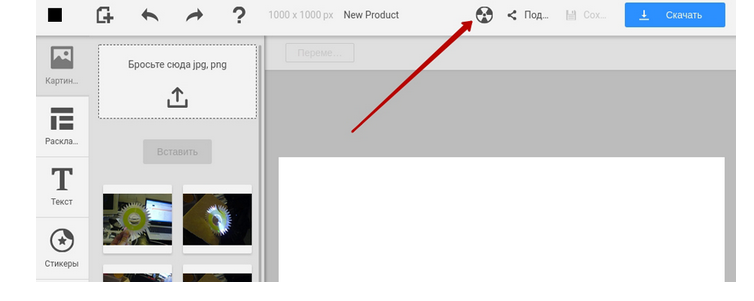
Специальная кнопка в шапке сайта
Но если критический баг все же состоялся, необходимо быстрее блокировать интерфейс, чтобы QA специалист не нажимал на кнопку по 10 раз, тем самым, не приводя себя в тупик.
window.onerror = (errorMsg, url, lineNumber, lineCount, trace) => {
…
// show BSOD
let bsod = BSOD(stackData);
document.body.appendChild(bsod);
…
};
Если случилась критическая ошибка на стейджинге, можно вывести «синий экран смерти».
Сверху виден текст со стеком определенной критической ошибки, а снизу – действия, которые ей предшествовали. Так же нам приходит оригинальный ID бага. Тестировщикам просто остается выделить его и прикрепить в запрос.
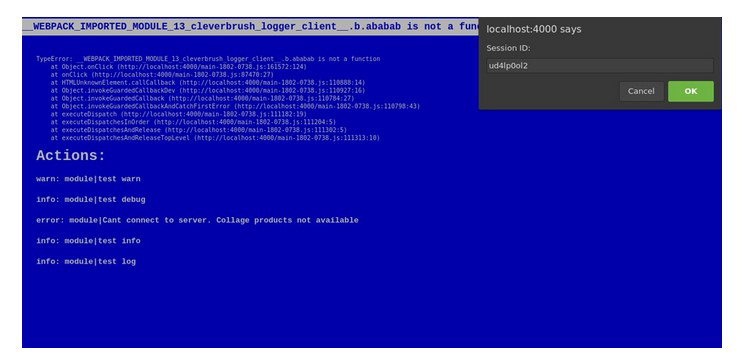
Синий экран смерти
Наш продукт весьма тесно взаимодействует с back-end. В таком случае эту часть также можно покрыть логированием. Для этих целей используем Winston + record в файл посредством middleware Express. Вышеупомянутый Logstash анализирует логи из файла и отсылает их в ElasticSearch. Для того, чтобы качественно объединить логи back-end и front-end, можно генерировать ID сессии и отправлять их в название каждого сформированного запроса:
rest.defaults.headers.common.sessionId = global.__session_id__;
То есть теперь понятно, если мы создали и отправили запрос, то он в любом случае выполнится на сервере. Нам будет приходить ответ, и мы спокойно сможем продолжать работу на стороне клиента. В Kibana будет проходить фильтрация по ID запроса.
Когда отправляется стек действия на ElasticSearch, QA специалисту приходит оригинальный ID номер, который он может прикрепить к запросам.
В итоге мы имеем:
- Все действия сохраняются в лимитированной коллекции, которая предшествует ошибке. Метаданные собираются по приложению;
- Сессия прикрепляется прямо с front-end на back-end через заголовки специальных запросов;
- Вывод ошибки по требованию;
- Блокировку интерфейса через пресловутый «экран смерти», если у QA специалиста возникает непредвиденная ошибка.

Что дает нам проверка логирования
Совет: проводите логирование продукта и на стадии выпуска, ведь только реальные пользователи, в отличие от даже самого опытного тестировщика, смогут найти узкие места функциональности вашего ПО.
Итак, логирование – это не только процедура нахождения ошибок, но и мониторинг действий клиента, сбор информации. Логирование может стать хорошим дополнением к продуктам Google Analytics и верификацией на пресловутый User Experience.








Оставить комментарий