
Каждый день в мире появляется все больше и больше разнообразного ПО для проведения нагрузочного тестирования. А значит, интерес к этой области постепенно начинает возрастать.
Базовая задача любого инструмента нагрузочного тестирования – подать требуемую нагрузку на систему. Но кроме этого, есть еще одна очень важная задача – представить полноценный отчет об итогах данной нагрузки. Иначе будет выполнено тестирование, но ничего стоящего сказать о его итогах, не получиться. К тому же не выйдет понять, с какого точно момента начинается ошибка, и какова ее природа.
На сегодняшний день очень востребованными являются такие инструменты нагрузочного тестирования:
- Gatling;
- MF LoadRunner;
- Apache JMeter.
Каждый из них обладает возможностями генерации тестовых данных в виде готовых отчетов. Также они могут предоставлять отдельные графики и часть необработанных данных, на основе которых непосредственно и формируется тестовый отчет.
Далее в статье речь пойдет об инструменте Gatling, на примере которого будут рассмотрены случаи использования такого ПО в повседневной трудовой деятельности QA-специалиста.

Логотип Gatling
Базовые метрики Gatling
Программа содержит большой перечень индикаторов, которые могут демонстрировать количественные и процентные соотношения распределения времени отклика запроса по изначально сформированным группам. Все это удобно структурируется в графики, которые очень легко использовать. Благодаря этому пользователь может давать предварительную оценку итогам проверок без дополнительного анализа прочих пластов информации.
Есть так называемые пороги перехода по группам, которые тестировщик настраивает самостоятельно. Представляется сразу три группы: с откликом менее 50 секунд, с откликом от 50 до 100 секунд и с откликом более 100 секунд.
Gatling позволяет самостоятельно настраивать пороги перехода по группам, а также их сумму в специальном файле gatling.comf. Графики такого вида лучше всего выстраивать на базе методики APDEX. Также можно добавлять индикатор с суммой выполненных запросов с ошибками (багами).
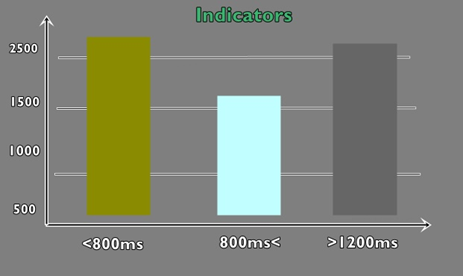
График индикаторов с количеством ошибочных запросов
Методика APDEX позволяет применять индикаторы в процессе выполнения регрессионного тестирования для процедуры сравнения версий релизов: так сразу будет понятно, насколько хуже или лучше стали сборки.
К слову, подобного графика нет изначально в MF LoadRunner и Apache JMeter, но его легко можно создать на основе dashboard в утилите Grafana.
Таблицы со временем отклика
По умолчанию, Gatling может выстраивать таблицу по перцентилям, максимальному и среднему времени отклика, а также по дефектам. По ней предоставляется возможность отслеживать выходы за пределы SLA.
Традиционно, в структуре SLA указывают перцентили 95 и 99 процентов багов. То есть таблица позволяет получить мгновенную оценку проведенных проверок.
Пример таблицы со временем отклика в Gatling
Если суммировать запросы в виде определенных транзакций, пользователь сможет увидеть в таблице оценку как некоторых запросов, так и всей группы запросов и транзакций одновременно.
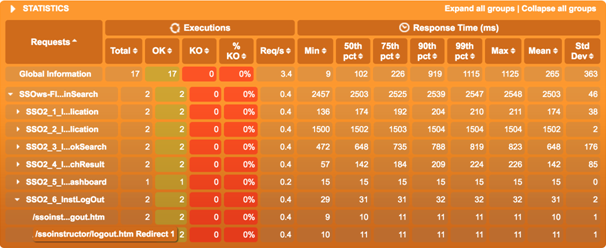
Пример отчета с оценкой запросов и времени отклика
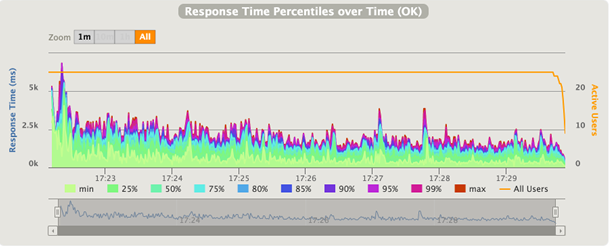
Графики виртуальных пользователей
Традиционно такие графики демонстрируют то, как пользователи заходят в тестируемое приложение, тем самым показывая реальный профиль загрузки приложения. Стоит отдельно отметить, что для инструментов MF LoadRunner и Gatling такие графики показывают сумму виртуальных пользователей, а вот для Apache JMeter – сумму потоков.
Обычно график используется для точного контроля корректности подачи требуемой нагрузки. Нужно, чтобы тестовый расчетный сценарий точно соответствовал тому, что будет подано в систему при реальных условиях.
К примеру, если вы обнаруживаете на графике достаточные отклонения от планируемого сценария в верхнюю сторону, значит, что-то пошло не по сценарию: дефект в расчетах, запущено больше, чем следовало, появились виртуальные копии инструмента и прочее.
Может быть, следующие графики уже и нет смысла анализировать, так как вы подали на 200 пользователей больше, чем хотели, когда система изначально проектировала для функционирования только 100 пользователей.
Данный график можно поделить на 2 равнозначных типа:
- Active users – показывает, какое количество потоков активно в данный момент. Когда потоки начинаются, особенно при открытой модели нагрузки, данный показатель может существенным образом колебаться на протяжении всего периода проведения тестирования.
- Total VUsers – демонстрирует, сколько потоков начались и завершились с момента начала теста. Очень удобно при закрытой модели нагрузки, в которой потоки не завершаются.
Тип графика также зависит и от непосредственно модели нагрузки:
- Закрытая форма – пользователи должны заходить в систему на основании планируемого профиля нагрузки. Если на графике отображаются провалы или пики нагрузки, значит, нагрузка пошла не по запланированному сценарию, и ее необходимо детально изучить.
- Открытая модель – на графике могут отображаться пики и провалы, и это нормально для данной модели. Пик на графике обязательно должен коррелировать при увеличении времени на отклик, так как в такой момент пользователи ждут ответа от сервера и нагрузка на систему может быстро падать. Чтобы защитить систему от чрезмерного роста суммы пользователей необходимо применять функции троттлинга, в принудительном порядке задавать верхний порог – максимальную сумму поднятых пользователей с помощью инструмента нагрузки.
Миллисекунды
Детально можно рассмотреть и такой параметр как миллисекунды (Latency) – текущее время задержки.
Данный параметр демонстрирует время между завершением отправки запроса до времени получения первого ответного пакета от тестируемой системы.
На основе параметра миллисекунд можно вручную измерять также некоторые задержки на сетевом уровне, если параметр будет возрастать. Рекомендуется, чтобы он всегда стремился к нулевой отметке.
Данный вид графиков в основном используется при максимально глубоком анализе и поиске багов производительности. К сожалению изначально данного графика нет в Gatling, так что придется настраивать его вручную.
В завершение отметим, что Gatling – это хороший инструмент, который позволяет не только быстро сравнить планируемую нагрузку с реальной, но и анализировать массу полезных и исчерпывающих метрик производительности. А это в свою очередь – основа для создания полезного и многофункционального программного веб-продукта.








Оставить комментарий